







The Model Thinker: What You Need to Know to Make Data Work for You
Scott E. Page
The Model Thinker: What You Need to Know to Make Data Work for You
本書のサンプルを目を通してみると、本文がチャーリー・マンガー氏の言葉の引用から始まっています。
ー賢明になるためには、頭の中にモデルを持つことだ。このモデルの格子の中に、直接の経験と、代行による間接的な経験の両方の配列を持つことだー
彼は、昨年(2023年)の11月に、白寿で他界されましたが、生前は投資会社バークシャー・ハサウェイでバフェット氏のパートナーであった人物です。
モデルを作りコードにしシミュレーションする、あるいはデータを分析することは、評者の日常業務の一つでもあり、本書のタイトルが興味深かったので読んでみました。
著者はサンタフェに関係した仕事に従事しています。複雑系のリサーチャーでサンタフェに籍を置いている、ドイン・ファーマ氏の著書『Making Sense of Chaos』が4月に出版されたため、読んだところでした。ファーマ氏は非合理的なエージェントを使って経済モデルのシミュレーションを継続していますが、これも現実社会の経済現象をモデル化する試みの一つです。
本書は、モデルとモデリングについて、複雑な現象を理解するための思考のアプローチを紹介しています。モデル思考は、多くの多様な論理的な枠組みを通して知性を生み出します。
本書は現実の問題に焦点を当てています。ここでは、モデルを世界の単純化、数学的な類似性、人工的な構造物の三つの分類に落とし込んで言及してあります。
モデルには三つの類似性があり、第一に簡素化、これは必要ない枝葉を分離し、現実を抽象化します。第二に、様式化し、正確な定義を作ります。これには言語ではなく数学を使います。簡素化と正確化によって、仮説を生成し、データを適合させ、解決策をデザインし、論理的に作業ができる扱いやすい空間を作ります。モデルは、私たちが、その中で論理的に考えることができる構造を作ります。
モデルがなければ、私たちはデータを取り込み、扱う能力が制限されます。モデルがあれば、仮定を明確にし、論理的に思考することができます。
ウィットゲンシュタインは「Tractatus」1の中で、”論理はそれ自身に留意する;私たちがしなければならないことは、それがどのように振る舞うか見て、把握すること”と書いています。論理は、説明、予測、コミュニケーション、デザインを助けますが、論理は、すべてのモデルは間違っているという、3番目の性質を導くコストに立ち向かいます。これはすべてのモデルに対して真実です。ニュートンの法則でさえ、確かなスケールの中だけで成立するものとして参照されます。
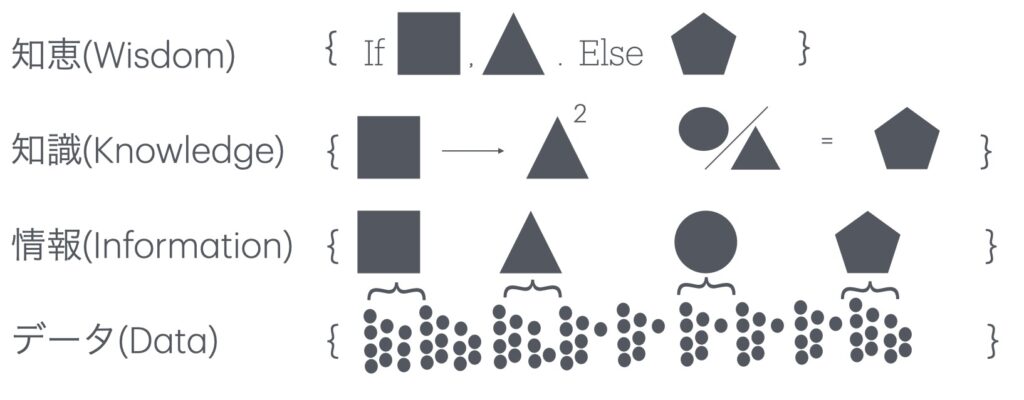
本書の1章に、T.S.エリオットの問い2から様式化した知性の階層として、モデルがどのようにデータを知性に変換するか図示されています。わかりやすいので略記して引用します。
図1 知性の階層
モデルには7つの使い方があります。推論、説明、デザイン、コミュニケーション、行動、予測、探索です。
本書の大半は多くの実際のモデルの事例が示されています。多重のモデルお枠組みを使って考える個人が、単一のモデルを使って予測する人々より、高い精度で予測するという証拠と同様に、数学的な事実は、コンピュータサイエンスにおける多重の分類による平均であるアンサンブル法の成功を説明します。
多くのモデルの平均は、典型的に最も良いモデルよりも良い結果を導きます。
仮に、私たちが、多重に多様で正確なモデルを構築できるならば、非常に正確に予測、評価し、良い行動を選択することができます。理論は、多くのモデル思考の論理の正当性を立証します。
モデルの使い方のうちの4つ、推論、説明、伝達、探索は簡素化を要求します。
また、人々が多くのモデルを適用するならば、間違いを犯すことが少なくなります。(Many-model思考)
本書の5章〜23章までは、実際のモデルに関して記述してあります。正規分布やlong tailsのPower-law分布、線形モデルなどが示されています。種々のモデルを紹介してありますが、個別のモデルに割く項数が限られているため、応用例をいくつか紹介するにとどまっています。最終章の23章にCOVID-19 パンデミックに関連して、複数のモデルを使ってその解析を紹介してあります。
非線形モデルに関して、少し取り上げてみます。
今年のストックホルムの経済学賞に選ばれた、アセモグル氏とロビンソン氏の共著書に「Why Nations Fail」があります。著書のテーマは、なぜ、成長に関して、いくつかの国で成功し、別のいくつかの国では失敗するのか。本書でも同様のテーマで非線形モデルとして一つの章が割かれています。それらの調査はここではモデルの値と制限を示します。
ここでのモデルは、私たちは低いGDPから急速な成長を成し遂げる国の能力から着手することができます。
長期の成長にはイノベーションが必要なことが、2番目のモデルで示されます。継続した成長にはイノベーションが必要になります。
1956年11月、ポーランド大使館で西側の大使に向けて、フルシチョフは告別式を提供するとスピーチしましたが、実際はそうはなりませんでした。彼らはそうすることに失敗しました。なぜならソビエトは技術革新(innovate)しませんでした。彼らは自由を制限し、アントレプレナーを窒息させました。
イノベーションの増加は乗数効果を生みます。私たちはそれらを乗算した効果を得ます。最初はイノベーション直接の効果で、2番目の生産物の増加は資本の増加から上昇します。
私たちは関数の形状の理解が不足し、そのために、しばしば線形的な推定をして、例えば、中国の経済が世界を追い抜くと推定します。日本のように成長してくると、成長は鈍化します。
モデルを使えば、非線形な効果を生み出す論理を通して、よりよく考えることができます。
非線形関数のセットは巨大です。本書の8章でた凹凸モデルを紹介していますが、これは広大な海の中で少し沈んだだけです。複雑な世界の中で、私たちの推論、説明、行動の能力を改善しようと望むなら、非線形な現象の中に深くダイブする必要があります。
GDPを指標にした経済成長モデルは、決して線形ではないため、急成長した中国の今後や、成長が鈍化した日本に関するモデルなどを非線形モデルで組みことができるでしょう。
本書は、現実社会に対して数学モデルを使って思考する事例を紹介してあります。教養としてどのようなモデルが使われているか知るには良い著書です。
- Tractatus Logico-Philosophicus(邦訳:論理哲学論考)は、哲学者がさまざまな解釈をしています。評者がTractatusを読んで認識した限りでは、哲学者による解釈にはどれも違和感があリました。
現代は、コンピュータが発明された後なので、言語、画像、動画、音声などが、デジタルで表現でき、デジタルで世界を写像することができるのは皆の知るところです。コンピュータはブール代数と2進法で動作しています。ウィットゲンシュタインは数学者としての基礎があり、Tractatusは、コンピュータがなかった時代に、集合論と論理学で世界を写像しようとした試みであると解釈した方がわかりやすいと思います。Tractatusは、”語り得ないものには、沈黙しなければならない”で終わっていることが有名で、著名哲学者によると、哲学論争に終止符を打ったのような解釈をしていますが、評者は、単に、”私は神を信じない”と言っているだけだと捉えています。神や精霊や不可解な現象に対するキリスト教的な解釈から距離を置いたものでしょう。彼は幼少期から神学校出身です。
彼がケンブリッジで数学基礎の教鞭を取った時の聴講生の一人にアラン・チューリングがいます。人工知能、コンピュータサイエンスは黎明期にも入っておらず、はっきりとした形にはなっていません。フォン・ノイマンが電子計算機の基礎概念を作るのは、これより後の時代になります。 ↩︎ - “Where is the wisdom we have lost in knowledge? Where is the knowledge we have lost in information?” To that we mighit add, where is the information we have lost in all this data?
↩︎
Tractatusについて
「The Model Thinker」内でウィットゲンシュタインの「Tractatus Logico-Philosophicus」から引用されていました。他の著書でもウィットゲンシュタインがよく引用されることがあります、良い機会なのでTractatusの書評も記しておきます。
機械学習に関して、大規模言語モデル(LLM)と類似のアルゴリズムを用いたツールに興味があったので、LLMの基礎概念に通じるウィットゲンシュタインの思索を知ることは有益でした。
彼の著作はTractatusのほか、1939年に彼がケンブリッジで行った講義を、生徒が記録したノートを基にまとめた著作があります。こちらには、後に暗号のエニグマを解読し、AIの分野ではチューリングマシンでよく知られたアラン・チューリングが講義を受ける側の質問者として登場しているようです。
この著作では集合論から言語がコンテキストとの相互の関係性の中でどのように位置づけられるか、現実世界を写す言語に対する洞察が記されています。
哲学者によるウィットゲンシュタイン論を追求するつもりはないため、哲学とは別の視点から彼の思索メモという位置付けで読みました。
長い文章による概念の説明ではなく、世界やコンテキストに関する論理が短いセンテンスで綴られていきます。内容は彼の抽象的な思索の羅列で、万民が持つ共通する知識基盤の上で、テーマを論じているのではありません。従って、彼固有の思索の概念として言語が世界を記述するというテーマを読み手が解釈することになります。受け手によって解釈が異なるかもしれませんが、彼が捉えた言語を使って世界を写像することに関する理解がメモにしてあります。
哲学を学んでいる方より、むしろ実際にニューラルネットを使って自動翻訳のアルゴリズムや生成AIについて考え、自然言語処理のプログラムを構築する分野にいる人の方が、オブジェクトやケース、ワード、アトミックファクトなどの彼が使用する概念を論理的に解釈して、咀嚼できるかもしれません。彼が確率論を導入して用いている”truth-grounds"という概念は、現在の機械学習の世界では、学習用のデータと予測データを検証するための正解データ(ground-truth)の意味で用いられています。
著書では、世界を写像する論理や言語機能を短いセンテンスで表現してあり、彼の言語や記号による現実世界のオブジェクトに対する洞察が短くまとめられています。
彼は知識基盤にが数学の概念があるので、集合、確率論なども記述されています。短い著作ですが、行間にある内容を深読みするより、短いセンテンスで表現された内容を、そのまま受け取ってリアリティやコンテキストを把握した方が良いでしょう。
彼は、ワードとオブジェクトの関係を1対1で対比するのでなく、コンテキストの重要性を指摘しています。
この著作の中で、重視したコンテキストは、近年の自然言語処理AIの分野で極めて重要になります。James C.Klaggeによる"Tractatus in context"という1922-1924の初期のレビューと反応を収録した著書でもコンテキストを重視している背景が記されています。
ニューラルネットを応用した自然言語処理の分野では、近年、word2vec->ELMo->BERT LLMと短期間で技術が進歩し、GPTのような生成言語モデルでも、ワードはコンテキストの中での相対的な位置付けが重要になります。
LLMではワードが文脈の中で変化することや、文脈との相互関係の中で意味が特定され識別されます。例えば、アラビア語ではある一つのワードが異なる文脈の中で10種類以上の異なる意味を持ちます。英語でもgetなどの動詞が前置詞と結びついて、日本語からは複数の多様な意味に解釈され、それぞれ別の動詞が対応します。
LLMは、この異なる言語間でのワードの指す概念の結びつきの曖昧さをニューラルネットの学習で実現します。この著作では、ワードの関係性を矛盾のない公理としてでなく、このゆるい定義のまま内在する矛盾を許容しています。この彼の言語に対する考えはニューラルネットで実装するアルゴリズムと親和性があります。
彼はコンピュータのない時代に、世界を表す言語の構造について深く思索しています。
公理を基にした数学的な厳密性と矛盾するように見える彼の考えは、当時のチューリングやその他の数学者には許容できそうにないことは推測できます。実際の彼とチューリングの質疑がケンブリッジでの講義をまとめた著作に掲載されているそうです。こちらも興味深いので目を通しておく価値があるでしょう。
{kind=link}