因果推論において、処置の個別の効果を把握するのに、ITE(Indivisual Treatment Effect)あるいは、CATE(Conditional Average Treatment Effect)を計算します。伝統的な機械学習の方法を使って因果の効果を計算する場合は、対象となるデータに適合する機械学習モデル、たとえば、ツリーをもとにした方法やニューラルネットワークを使います。本稿ではNeyman-RubinのPOフレームワークを使って、バイナリの処置効果の推定のために、meta-learnerと呼ばれる機械学習の相違を比較します。S-learner, T-learner, TARNet, CFRNet, DragonNetを取り上げます。
因果推論と機械学習
因果推論のケースで、共変量XとZを使ってYを予測するための教師あり学習モデルを訓練することを考えます。
すでに何度か取り上げたdo-Calculusの例のようなPearlの因果推論のアプローチでなく、Neyman, Rubin の潜在的な結果:PO(Potential Outcomes)のフレームワークを使います1。全体や平均レベルより、個別レベルの因果の効果の推定に焦点を当てます。分類のアルゴリズムを使った処置の効果の計算にニューラルネットワークの深層学習を適用します。
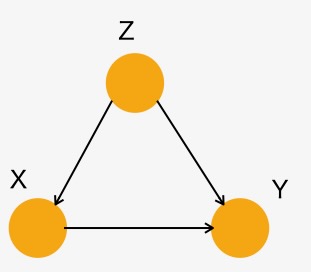
以下のような単一の交絡因子がある調整式(adjustment formula)
\[ P(Y=y) | do(X=x)) = \sum_{z} P( Y=y | X=x, Z=z) P(Z=z) \]
この調整式は、交絡因子 Zがあるときに、結果 Yに対する処置 Xの効果を推定する方法です。
図1 単一の交絡因子
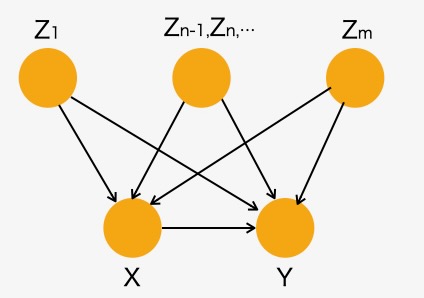
下図2に示すように交絡因子Ziが複数ある場合、調整式は以下のようになります。
\[ E[Y=y | do(X=x)] = \sum_{z} E[Y=y | X = x, Z_{1} = z_{1}, ..., Z_{p} = z_{p}] \]
この条件確率の項は、教師あり機械学習で正確に量を測ることができます。観測データからこれらの量を計算することで因果の効果を推定することができます。
図2 複数の交絡因子
このように複数の交絡因子がある場合、データをもとにして機械学習の方法を使って結果を予測することができます。調整式を評価するための教師あり学習モデルは、meta-learnerと呼ばれます。
画像の分類のような、伝統的な教師あり学習では、正解のラベルがわかっています。モデルの正確性は、予測と正解ラベルを比較することで簡単に計算できます。因果推論の場合、正解ラベルであるCounetrfactual の結果は観測できません。知ることができるのは処置に対応する結果のみです。
図3 処置Tの結果
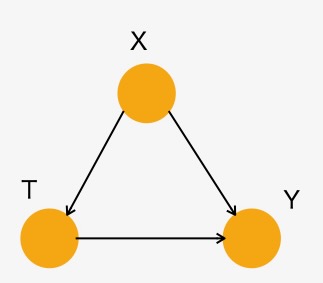
観測結果Yは、割り当てられた処置に依存します。
\[ Y = T * Y(1) + (1-T) * Y(0) \]
これは、もし個別の対象が処置されていれば(T=1)、Y(1)だけが観測され、個別の対象が処置されていなければ(T=0)、Y(0)だけを観測することを意味しています。
本稿にはCATENetsを使ったシミュレーションのサンプルコードを含んでいます。(CATENetsはPyTorchで実装したmeta-Learnerのライブラリです)
Counterfactual結果のシミュレーションの優位性は、各個別の対象毎にY(0),Y(1)の両方にアクセスすることです。これは任意の共変量Xに対して、真のITE(Indivisual Treatment Effect)を計算することができます。
\[ \tau (X) = Y(1) - Y(0) \]
そして、ITEの平均を取ることでATEを計算することができます。
\[ ATE = E[ \tau(X) ] \]
meta-learnerは、処置効果の推定問題を幾つかのサブ問題に分離して、それぞれに教師つき学習方法を使って解決するものです。meta-learnerとして、以下の項でS-Learner, T-Learnerを概観します。
S-Learner
S-Learnerは単一(Single-Learner)の学習を処置変数と処置済みと未処置データを含むデータセットをトレーニングして、潜在結果を予測します。
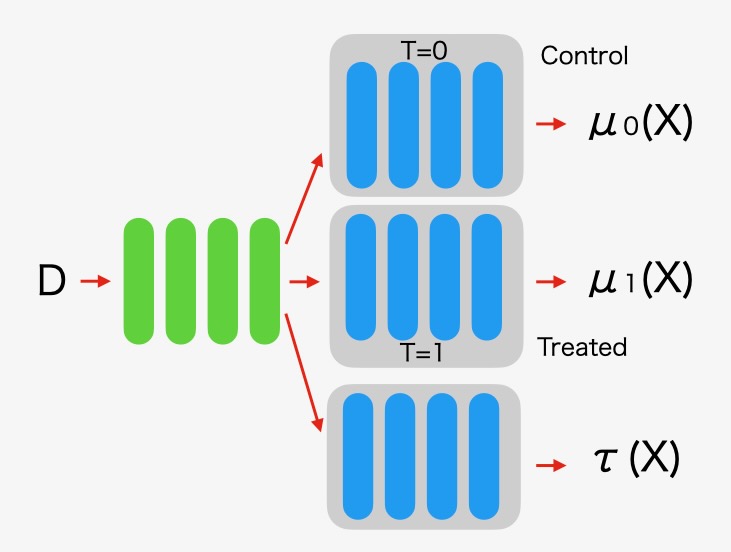
S-Learnerは、調整関数を評価するための簡単な方法です。処置データと未処置データの学習に同じ学習モデルを用います。図示すると以下のようにモデルです。
図4 S-Learnerアーキテクチャ

\[ \tau^{~} _{CATE} = \mu ( X, T=1 ) - \mu ( X, T=0 ) \]
時系列データを使って、共変量xと交絡因子Zからなる機械学習モデルfを訓練します。Yが断定的な分類の場合、分類のアルゴリズム、連続データの場合は回帰のアルゴリズムを使い、各観測データに対して予測します。
\[ ATE = E[ Y | do(X=1) ] - E [ Y | do(X=0) ] \]
T-Learner
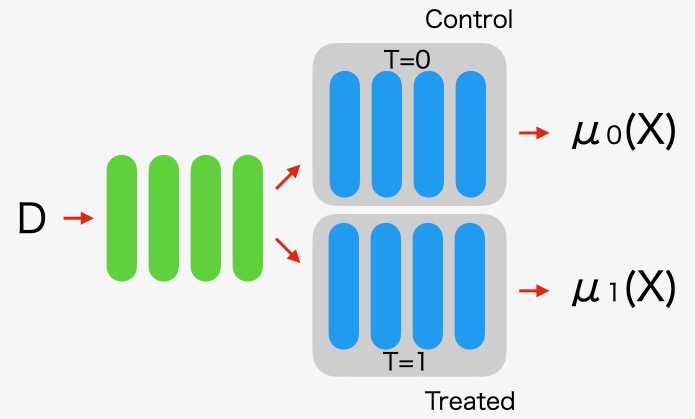
T-Learner(Two-Learner)では、処置データと未処置データ(照合基準)の学習に別々のモデルを使います。図示すると以下のようなモデルです。
図5 T-Learnerアーキテクチャ
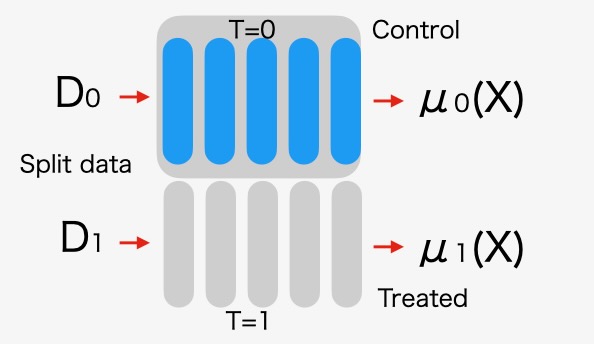
\[ \tau^{~} _{CATE} = \mu_{1} ( X) - \mu_{0} ( X ) \]
入力データを処置データと未処置データの二つに分離します。それぞれのサブセットに対して別々のニューラルネットを割り当てます。
SNet
SNetは初期レイヤーが並列なネットワークから構成されます。
SNetのSは、初期の関係性から取得する情報が後処理のタスク固有のヘッドで共有(Shared)されることから取られています。
次項に記すTARNetの拡張したものです。TARNetの共有層がマルチヘッドになっています。
TARNet
Treatment-Agnostic Representation Network、2017年、Uri Shalit等によって発表されました。
図6のような3ヘッドのニューラルネットワークです。共有レイヤーに入力されたデータが、処置の状態によってT-Learnerに入力されます。出力はCATEの計算に用いられtます。
図6 TARNetアーキテクチャ
これは、テキストを交絡因子とみなしたときの言語処理に使えます。BERTアーキテクチャを拡張した自然言語処理のアーキテクチャを作ります。CausalBERT2は、下の項で示すのDragonNetと同様にTARNetをもとにしています。
Conditional Treatment Effect (CATE)を計算するのに、サンプルコードとしてCATENetsライブラリを使います。PyTorchを基にしたライブラリです。以前、強化学習を使った因果探索アルゴリズム、gCastleを紹介しましたが、このライブラリも同様にtorchを使って実装されています。torchによるコードは構造がわかりやすく簡潔にまとまっており、ライブラリはsklern形式のラッパーが実装されてます。
ソースコードは以下のGitから参照することができます。
https://github.com/AliciaCurth/CATENets
実装は、ケンブリッジ大学のAlica Curth氏の以下の論文をもとにしています。
- Alicia Curth, Mihaela van der Schaar. 2021 "Nonparametric Estimation of Heterogeneous Treatment Effects: From Theory to Learning Algorithms"
以下、CATENetsライブラリでのTARNetの使用例です。
from catenets.models.jax import TNet, SNet
from catenets.experiment_utils.simulation_utils import simulate_treatment_setup
from catenets.models.torch import DragonNet, TARNet
# simulate some data (here: unconfounded, 10 prognostic variables and 5 predictive variables)
X, y, w, p, cate = simulate_treatment_setup(n=2000, n_o=10, n_t=5, n_c=0)
# estimate CATE using SNet
s = SNet(penalty_orthogonal=0.01)
s.fit(X, y, w)
cate_pred_s = s.predict(X)
# TARNet
model = TARNet(X_train.shape[1], batch_size=1024, n_iter=10)
model.fit(X_train, Y_train, W_train)
out = model.predict(X_test) # without potential outcomes
assert len(out) == len(X_test)
out, p0, p1 = model.predict(X_test, return_po=True) # with potential outcomesCFRNet
一般に、観測データの因果推論においては、選択バイアスを処理します。
処理データと未処置データでそれらの共変量が体系的に異なる場合、単純な比較では因果の効果はバイアスのかかった推定を導きます。この問題は、交絡、または共変量のインバランスとして知られています。
CFRNetは共変量の表示を学習します。処置グループと未処置グループの共変量の影響のバランスを取るためです。
因果推論では、処置の影響それ自身の効果を分離して探します。処置に影響された共変量の効果ではありせん。CFRNetではニューラルネットを使ってバランスの取れた表示を学習することによって、この調整を自動で実行します。
以下の図7は、TARNetを拡張したCFRNetアーキテクチャです。
図7 CFRNetアーキテクチャ
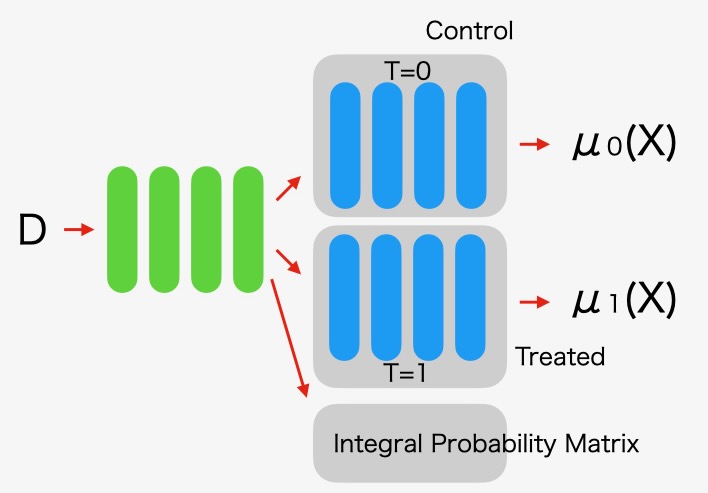
最初の共有層で特徴を抽出して、バランスの調整を計算します。
以下は、損失関数の構造です。予測損失とバランス損失を組み合わせています。
\[ Loss = L _{prediction} + \alpha * L _{balancing} \]
予測損失は、
\[ L_{prediction} = \frac {1}{n} \sum^{n}_{i=1} \left( T_{i} *(Y^{predicted}_{i}(1)-Y_{i})^{2} + (1-T_{i}) * (Y^{predicted}_{i}(0) - Y_{i})^{2} \right) \]
バランス損失は、二つの分布の差分を計測するIPM (Integral Probability Metric)という統計的な距離を使います。IPMは、MMD(Maximum Mean Discrepancy)またはWasserstein距離です。
以下の図8はバランス損失を示すCFRNetの処理の概要です。
図8 Representation imbalance
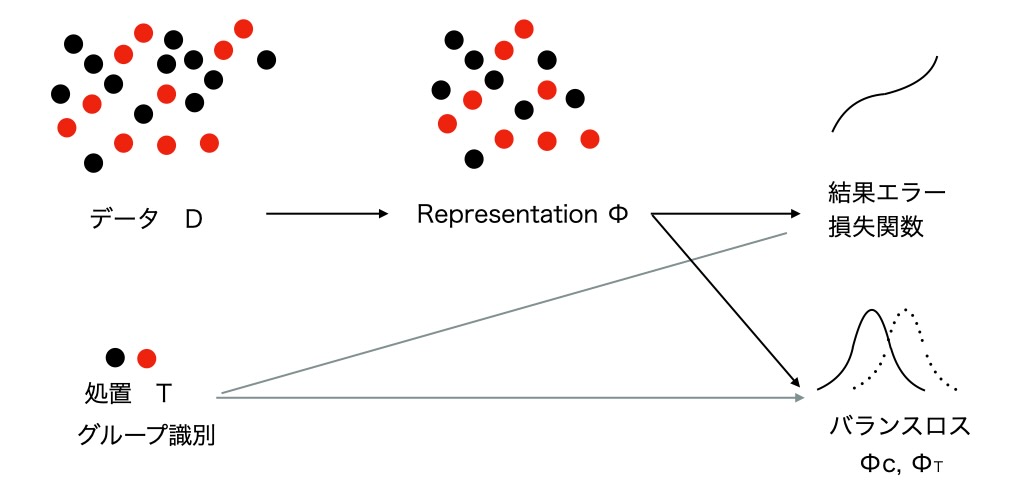
出力結果Yの予測のためにバランス損失を最小化します。図8の右下にあるRepresentation ΦのTとCの分布のズレです。T(treatment処置データT=1),C(control 未処置データT=0)を意味しています。分布のずれであるバランス損失は、ニューラルネットの共有層で自動的に計算されます。
CFRNetのオリジナルコードは、TensorFlow0.12 で実装されています。これはKerasを統合する前なのでKerasのAPIは含まれていません。以下のGitで参照することができます。
https://github.com/clinicalml/cfrnet
DragonNet
CFRNetと同様に、TARNetを拡張したアーキテクチャです。
以下の図9にDragonNetアーキテクチャを図示します。TARNetのモデルに、傾向スコア3の計算にも独立した学習層を作り4つのヘッドからなるネットワークです。
図9 DragonNetアーキテクチャ
傾向スコア(Propensity Score)とは、与えられた観測された共変量の中で処置や介入を受ける確率のことです。
図10は、傾向スコアのモデルを図示したものです。
図10 傾向スコア
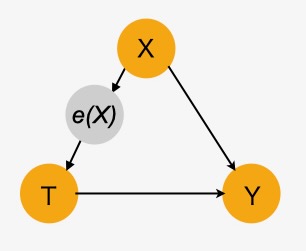
傾向スコアは以下のように定義しています。
\[ e(X) = P(T | X) \]
ここで、Tは処置インジケーターです(T=1:処置済み、T=0:未処置)
傾向スコアの条件下で共変量Xと処置変数Tは独立になります。
\[ T \bot X | e(X) \]
これを傾向スコアの理論と言います。
XとTの間の完全な中間ノードとして使うことができます。これはTとYの間にバックドア経路を与えます。これは処置と結果の間で交絡を削除します。
傾向スコアは処置グループと未処置グループ間のバランスを取るのに使われます。バランスの取れていないデータセットを取り扱うために機械学習で、リサンプリングし、重み付けする技術として使用されます。
図9に示すように傾向スコア e(X) は共有層を通過した後、独立した層のニューラルネットで、処置の確率を計算します。DragonNetの損失関数は、以下のように定義されています。
\[ L_{DragonNet} = L_{prediction} + \beta * L_{propensity} + \lambda * L_{targeted} \]
DragonNetの予測損失は、CFRNetの予測損失と同じ形式です。
\[ L_{prediction} = \frac {1}{n} \sum^{n}_{i=1} \left( T_{i} *(Y^{predicted}_{i}(1)-Y_{i})^{2} + (1-T_{i}) * (Y^{predicted}_{i}(0) - Y_{i})^{2} \right) \]
傾向予測損失は、処置Tと予測された傾向スコアe(X)のクロスエントロピーとして定義してあります。
\[ L_{propensity} =- \frac{1}{n} \sum^{n}_{i=1} \left( T_{i} log( e^{~}(X_{i})) + (1-T_{i}) log(1-e^{~}(X_{i})) \right) \]
Targeted RegularizationはDragonNetにユニークな項として追加されています。通常の目的関数は、$$L_{prediction} + \alpha * L_{propensity}$$で成立します。パラメータεと調整項を追加して、修正した目的関数を最小化することでモデルを訓練します。この項、Targeted調整損失は、学習した傾向スコアの平滑化関数として機能します。
CATENetsのライブラリにtorchベースのDragonNetの実装例が含まれています。
CATENets / catenets / models / torch / representation_nets.py
傾向予測損失は、pyTorchを使った実装ではnn.CrossEntropyLoss()関数を呼び出すだけです。
class DragonNet(BasicDragonNet):
"""
Class implements a variant based on Shi et al (2019)'s DragonNet.
"""
def __init__(
self,
n_unit_in: int,
binary_y: bool = False,
n_units_out_prop: int = DEFAULT_UNITS_OUT,
n_layers_out_prop: int = 0,
nonlin: str = DEFAULT_NONLIN,
n_units_r: int = DEFAULT_UNITS_R,
...参考資料
- Rubin, Donald B. 1974 "Estimating causal effects oof treatments in randomized and nonrandomized studies."
- Alicia Curth, Mihaela van der Schaar. 2021 "Nonparametric Estimation of Heterogeneous Treatment Effects: From Theory to Learning Algorithms"
- Victor Veitch, Dhanya Sridhar, Devid M. Blei. 2020 "Adapting Text Embeddings for Causal Inference. "
- Rosenbaum, Paul R., D.B.Rubin. 1983 "The central role of the propensity score in observational studies for causal effects"
- Uri Shalit, Fredrik D. Johansson, David Sontag. "Estimating individual treatment effect: generalization bounds and algorithms."
- Claudia Shi, David M. Blei, Victor Veitech. 2019 "Adapting Neural Networks for Estimation of Treatment Effects."
脚注
- RubinのPOフレームワークは、医療・治験分野で応用されているため、個別のITEに着目します。DAGフレームワークとの関係では、Pearlが"The first law of causal inference"というように、片方のフレームワークで正しい結果は、もう一方のフレームワークでも正しいという関係があります。二つのフレームワークは同じ結果を導きます。両者でATEを示すと次式の関係になります。$$ATE = E[Y_{1} -Y_{0}] = E[ Y | do(T=1)] - E[ Y | do(T=0)] $$ ↩︎
- Victor Veitch, Dhanya Sridhar, Devid M. Blei. 2020 "Adapting Text Embeddings for Causal Inference. " ↩︎
- Rosenbaum, Paul R., D.B.Rubin. 1983 "The central role of the propensity score in observational studies for causal effects." ↩︎
あるいは、CATE(Conditional Average Treatment Ef ){kind=link}