







LSTMはRNNの一つですが、言語処理向けに開発されてきました。
Pythonのコンファレンスで、いくつかLSTMを用いた株価予測に関してプレゼンがあったので検討してみました。
LSTM
金融市場の多くのモデルは、効率的市場仮説(以下 EMH)を前提にしています。
株価の時系列データはランダムであり、ドリフトフォース(トレンド項)にランダムな要素を加味してモデル化されています。
ブラウン運動と同じモデルです。
一方、言語の時系列データは、自然発生的に法則性を内在して形成されています。
言語のワードの順序は、プレフィックス、ポストフィックスなどに決まったパターンがあり、言語の文法として体系化されています。
これは、ニューラルネットワークによって学習することができます。LSTMはそうした文法の学習など、言語処理系のアプリケーション向けに作られています。
LSTMに正弦波を学習させた例があります。
正弦波は明確に規則性のあるデータです。
LSTMに学習させて出力した例では、振幅が徐々に現象する点はあるのですが、正弦波を再現しています。
では、果たして株価の時系列データをLSTMに学習させた場合、LSTMは何らかの法則性をデータから抽出できるでしょうか。
これは株価の時系列データに私たちの知らない何らかのパターンが存在しており、それを機械学習によって抽出してみようという試みです。
時系列データのパターンが既知であれば、LSTMにそのパターンを学習させることは可能です。
機械翻訳では、翻訳の誤りを外部から訂正することで翻訳の精度を上げていきます。
モデル
以下のモデルを検討してみましょう。
N日後の株価の上昇、下落を予測させるモデルです。
ここでは先物価格の時系列データを使って、翌日の株価を予測させます。
LSTMの実装には、tensorflowをバックエンドにしたKerasを用います。
学習モデルは、一定の期間単位の株価を読み込み、翌日の株価が上昇したか、下降したかを学習させます。
予測精度が50%を超えるようであれば、データから法則性を抽出していると言えます。
取引コストを差し引いて、取引回数を重ねると、実際の運用に有効であるとみなせます。
Kerasのインターフェイスを使ってPythonで組んでみます。
トレーニングエポック数:32
バッチサイズ:32に設定してネットワークを学習します。
入力層 ドロップアウト0.2 lstm lstm dropout densemodel = Sequence()
model.add()
model.add(Dropout(0.2))
...
model.add(Dense(1))
....上記のように、Kerasではモデルに層を追加していくことで、多層ニューラルネットワークを簡単に組むことができます。
損失関数に mse, 最適化アルゴリズムには adam を使用してモデルをコンパイルします。
学習データにはTopixの先物データを使います。
では実行してみましょう。
以下は、Jupyter上で実行した結果のスクリーンショットです。
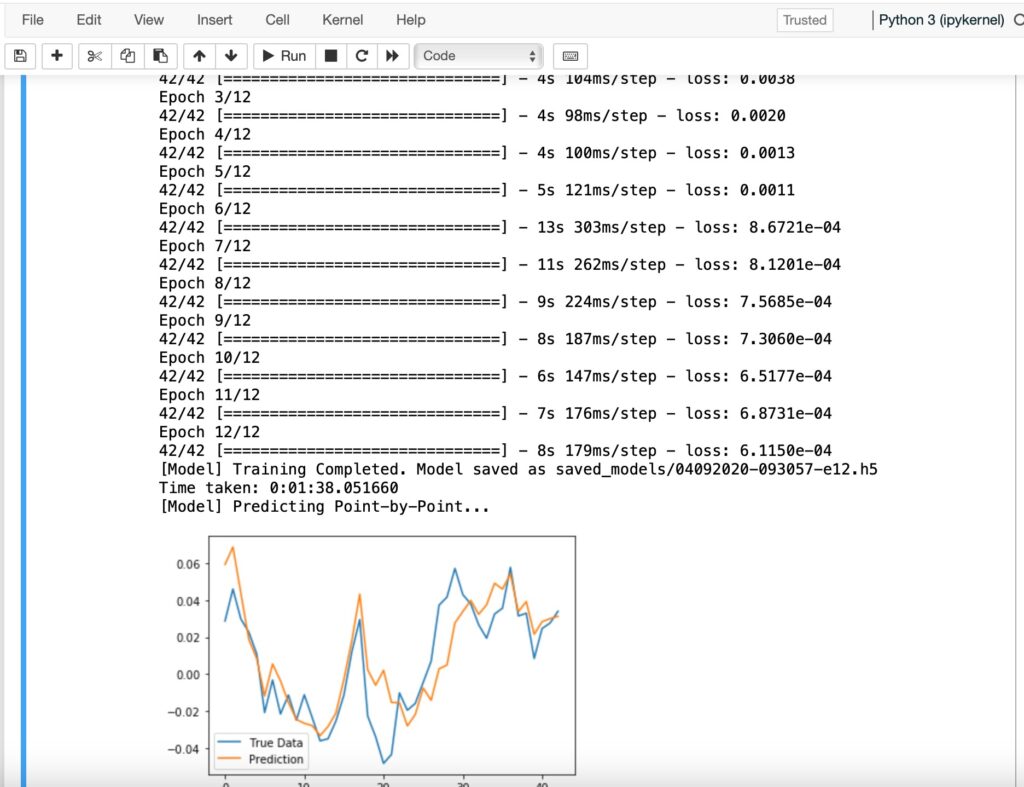
予測結果
今回の学習データの中で、そのカテゴリー(次のN日後の価格の上下変動)に分類できる特徴量の抽出は見られません。
学習データを変えて、様々な条件下で試してみると、季節要因やその他の要因による規則性を見出す可能性はあります。
特定のデータから市場の特異点を抽出することができるかもしれません。
多くのデータを用いて、詳細に検討してみるのも良いでしょう。
他のモデルを用いた手法で、より良い結果をもたらす候補がいくつかあります。
そちらの手法を洗練させることにしますが、機械学習は発展途上の分野で様々な手法と応用例があります。
他の様々な手法を検討しても良いでしょう。
{kind=link}